|
В предыдущих частях мы изучили свойства и методы как самого TreeView, так и его объектов, изучили его визуальное представление на экране, а также метод его "заселения". Настало время поработать с реальными таблицами.
Как было показано в предыдущей части, для ввода данных в TreeView используется метод Add коллекции Nodes. Есть одна особенность, связанная с ключом узла. Он должен соответствовать следующим требованиям:
- ключ должен представлять собой симольное выражние
- ключ не может начинаться с цифры
Примеры:
- неверные значения ключа, которые вызовут генерацию ошибки
- "правильные ключи"
- "_3"
- "_1test"
- "RS_20040706_collected_data"
Небольшое отступление: при первом же строительстве дерева вы ощутите всю полезность нормализации таблиц и использования синтетических ключей, не связанных со значениями какого-либо/каких-либо полей.
В качестве узла ключа, я всегда использую первичный ключ таблицы или ключ candidate из свободной таблицы. (Они у меня всегда синтетические - либо автогенерируемые, либо определяемые какой-либо пользовательской функцией.)
Тактика заполнения TreeView.
Сколько узлов должно располагаться на первом уровне иерархии? 100? 200? 1000? 500000?
Чем меньше, тем лучше. И это связано не с параметрами компьютера, на котором будет работать ваше приложение, но с параметрами пользователя. Из своего опыта могу сказать - не более 3-4 объемов данных, располагающихся в видимой части TreeView. Лучше немного поработать и разработать удобный для пользователя интерфейс, позволяющий быстро отбирать необходимые порции данных. Для алфавитных списков - это могут быть просто одна/две строки меток, в качестве Caption, которых используются буквы алфавита, для получателей - группировки по географии, объему поставок, типу закупаемого оборудования, для организаций - группировки по отделам. Как видим, здесь очень большую роль будет играть правильно спроектированная база данных.
Положим, что все это у нас есть. Уровни иерархии могут быть очень глубокими и, следовательно, строительство дерева может потребовать достаточно большого промежутка времени. Как поступить в таком случае? Очень просто - не строить все дерево сразу, а достраивать его постепенно, по мере необходимости. Положим, что сначала мы вводим в дерево первый уровень иерархии и отобажаем его пользователю. Но! Первичное дерево в таком случае выглядит не совсем так, как хотелось бы! Положим у первого и второго узла есть потомки, у третьего их нет, у четвертого есть и так далее. Поскольку узлам, имеющих (по базе данных) потомков, мы не поставили ничего в качестве дочерних узлов, все узлы выглядят одинаково и нет ни одного плюса, говорящего о том, что какие-то потомки имеются. А хочется, чтобы дерево выглядело так:
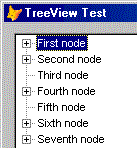
то есть, чтобы пользователь видел, что у узла есть потомки, то есть какие-то связанные данные. Как это сделать? Очень просто - введением ложного дочернего узла. Это может выглядеть так:
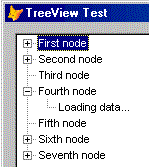
А откуда взять сведения, что узлы имеют потомков? Решений масса - от вспомогательных курсоров, до быстрых выборок, тем более, что эти выборки, при грамотно выстроенной базе двнных, простые по синтаксису и, как правило, полностью оптимизируемые.
При этом ложный узел имеет очень специфичный ключ, который формируется из ключа родительского узла с добавлением суффикса "_с0". Зачем? Для того, чтобы просто и гарантированно удалить ложный узел, при завершении строительства дочерних узлов, выбранного узла.
Ну, например, это может выглядеть так
- заполняем TreeView с вводом ложного узла:
Local lcPKey, lcCKey, lcDummyNodeText
lcPKey=""
lcCKey=""
lcDummyNodeText="Loading data..."
lcPKey=some_table.primary_key_tag_name
...
Checking some condition for child records presence
...
TreeViewObject_hierarchy.Nodes.Add(,,lcPKey,some_table.some_valuable_field)
If some_condition>0
lcCKey=lcPKey+[_c0]
TreeViewObject_hierarchy.Nodes.Add(lcPKey,4,lcCKey,lcDummyNodeText)
Endif
Далее смотрим - что может сделать пользователь. Если мы установили для TreeView свойства Style и LineStyle равными соответственно 7 и 1, то пользователь видит компонент в том виде, как он показан на рисунках выше. При этом пользователь может раскрыть нужный ему узел как с помощью щелчка мышью на крестике у соответствующего узла, так и произведя двойной щелчок на этом узле. В обоих случаях сработает событие Expand. Метод ассоциированный с этим событием получает в качестве параметра объект узла, который подлежит раскрытию.
Теперь достаточно ввести дочерние узлы первого уровня,используя тот же принцип, что и для первого уровня иерархии родительских узлов, и затем удалить ложный узел. Это может выглядеть так:
* append child nodes
...
...
...
* remove dummy node
lcKey2Remove=node.Key+[_c0]
This.Nodes.Remove(lcKey2REmove)
Аналогичные действия можно произвести и для свертывания узла. В таком случае срабатывает событие Collapse и можно вычистить дерево, используя следующий синтаксис:
If !(Right(Node.Child.Key,3)=[_c0])
Do While Node.Children>0
lcChildKey=Node.Child.Key
This.Nodes.Remove(lcChildKey)
Enddo
Endif
lcCKey=Node.Key+[_c0]
lcDummyNodeText="Loading data..."
This.Nodes.Add(Node.Key,4,lcCKey,lcDummyNodeText)
Остался еще один нерешенный вопрос. Принцип частичного формирования дерева определен, а как определить - какой узел достраивать и откуда брать данные?
Как я уже говорил ранее, TreeView не имеет источника данных и абстрагируется от них. Стало быть, нужен какой-то указатель. И опять таки масса вариантов. В качестве одного из них я использую иногда, на мой взгляд, простое и оригинальное решение.
Перед тем как строить дерево, вы уже решили какие данные и из каких таблиц будут вводиться в дерево. Положим, что у вас 4 уровня иерархии:
- Родитель
- Потомки
- Внуки
- Правнуки
Для дерева будет использованы 4 нормализованные таблицы. Что нам мешает создать переменную в форме и занести в нее перечень таблиц? Скажем в такой форме:
table1\table2\table3\table4
Вам это ничего не напоминает? Разумеется - свойство FullPath узла возвратит точно такую же последовательность меток с использованием разделителя "\" определяемого по умолчанию в свойстве PathSeparator. То есть, используя подсчет разделителей в FullPath мы можем установить таблицу, из которой нужно провести заполнение дочернего уровня или вывести из нее какие-то данные в другие элементы управления на форме, для отображения пользователю. И уже слышится вопрос - а команду откуда взять? А из того же дерева, например, только надо заранее об этом побеспокоится и использовать свойство Tag узла. Как? Об этом чуть дальше.
А пока займемся рутиной - заполнением дерева из базы данных.
Будет продолжено...
|