|
Вернемся к простейшему XML документу, приведенному во введении.
<?xml version=”1.0” standalone="yes"?>
<databasess>
<tables>Projects</tables>
</databasess>
Первая строка <?xml version=”1.0” standalone="yes"?> является частью пролога документа и представляет XML декларацию, состоящую из инструкции по обработке документа (processing instruction) - <?xml ... ?> и двух аттрибутов - version и standalone. Каждый XML документ начинается именно с XML декларации, включающей в себя обязательный аттрибут "vesrion", указывающий на используемую версию языка. Второй аттрибут "standalone" указывает на то, что весь документ содержится именно в этом файле и не требует импорта других файлов.
Все, что располагается ниже пролога, представляет собой содержание документа. XML документ представляет собой древовидную структуру, то есть, состоит из узлов. (Вам это ничего не напоминает?) В отличие от HTML, XML требует обязательного наличия открывающего и закрывающего тэгов, обрамляющих содержание документа. В данном файле это тэги <databasess> ... </databasess>, являющиеся корневым узлом документа. Внутри корневого узла размещен дочерний узел <tables>...</tables>. И внутри этого узла размещен текст, несущий какую-то информацию. Все вместе представляет собой так называемый well-formed XML document - хорошо сформированный документ. Кроме того, это еще и valid document, то есть "правильный" или действительный.
О чем нам может рассказать такой документ? О том, что он описывает некоторую базу данных, в которой имеется таблица Projects
Дополним наш документ еще одной строкой, и пусть он теперь выглядит так:
<?xml version=”1.0” standalone="yes"?>
<databases>
Common
<tables>Projects</tables>
</databases>
Теперь нам известно уже чуть больше. Этот документ описывает не какую-то абстрактную базу данных, а конкретную - "Common". Что мы сделали? Мы вставили текст в корневой узел, что также допускается и при этом документ остается по прежнему "well-formed" и "valid". А если мы желаем описать в одном единственном документе n-ое количество баз данных? К счастью, нет ничего проще. Поскольку XML-документ может содержать только один корневой узел, то мы просто добавляем в него новые дочерние узлы realdb и описываем в них наши базы данных. Используя эту же логику составления документа, с помощью любого текстового редактора, например, Notepad, создадим XML файл приведенного ниже содержания и сохраним его как "second_no_xslt.xml".
<?xml version="1.0" standalone="yes"?>
<databases>
<realdb>
<dbname>Common</dbname>
<tables>
<tablename>Projects</tablename>
<fields>
<fieldname>id</fieldname>
<fieldname>description</fieldname>
<fieldname>remarks</fieldname>
</fields>
</tables>
<tables>
<tablename>Team</tablename>
<fields>
<fieldname>id</fieldname>
<fieldname>pid</fieldname>
<fieldname>last_name</fieldname>
<fieldname>first_name</fieldname>
</fields>
</tables>
<tables>
<tablename>Previsions</tablename>
<fields>
<fieldname>id</fieldname>
<fieldname>startdate</fieldname>
<fieldname>enddate</fieldname>
<fieldname>version</fieldname>
</fields>
</tables>
</realdb>
<realdb>
<dbname>Divisions</dbname>
<tables>
<tablename>Headoffices</tablename>
<fields>
<fieldname>id</fieldname>
<fieldname>description</fieldname>
<fieldname>mail_address</fieldname>
<fieldname>city</fieldname>
<fieldname>province</fieldname>
<fieldname>state</fieldname>
</fields>
</tables>
<tables>
<tablename>Budgets</tablename>
<fields>
<fieldname>id</fieldname>
<fieldname>year</fieldname>
<fieldname>incoming</fieldname>
<fieldname>taxes</fieldname>
<fieldname>turnover</fieldname>
<fieldname>profit</fieldname>
</fields>
</tables>
</realdb>
</databases>
Вы можете взять этот первый файл здесь и посмотреть - как он выглядит в Internet Explorer. Можете пощелкать по минусам/плюсам и посмотреть, как меняется отображение файла.
Но поскольку предметом нашего рассмотрения является использование XML с Visual FoxPro, то посмотрим на структуру этого файла глазами лисы. "Что-то здесь не то", сказала бы лиса и была бы права. Fox, равно как и другие системы управления реляционными базами данных, оперирует с плоскими таблицами, то есть, если представить их в перевернутых декартовых координатах, с точкой отсчета, располагающейся в левом верхнем углу, то по оси Y будут располагаться строки записей, а по оси X - поля записей и при пересечении нужной строки с нужным столбцом, мы получаем содержимое столбца для этой записи.
Какую информацию из этого файла мы можем получить, исходя из выше сказанного? После парсинга таблица должна содержать две записи, так как у нас есть два узла realdb, находящихся на первом уровне иерархии узлов. Таблица будет содержать поле dbname, и соответствено первая запись будет содержать значение common и вторая divisions. А дальше? Вот тут уже проблема. На одном уровне иерархии с dbname расподагаютcя узлы, обрамленные тэгами tables, которые образуют второе поле таблицы. Но что они будут содержать? Записей две, а таблиц для первой базы данных приведено три, а для второй две. Не будем гадать и произведем экспорт файла в курсор, используя родную функцию VFP XMLTOCURSOR(), для чего выполним последовательность команд:
=XMLTOCURSOR("c:\vfptests\second_no_xslt.xml","second",512)
BROWSE

Что мы имеем? Налицо, соверщенно оправданная структурой плоских таблиц, потеря информации, содержащейся в файле. Давайте разберемся, как XMLTOCURSOR мог бы получить такую информацию.
Попробуем разобраться с работой парсера, вовлеченного в процесс получения курсора из XML файла. Как мы выяснили выше, в курсоре могут быть сформированы две записи, соответствующие тэгам realdb, что соответствует значению childNodes.length корневого узла XML-документа:
* создаем объект парсера XML
oXMLDom=CREATEOBJECT("MSXML2.DOMDocument.4.0")
* загружаем в него наш файл
oXMLDom.load("c:\vfptests\second_no_xslt.xml")
* получаем объектную ссылку на корневой элемент
oXMLRoot=oXMLDom.documentElement
* получаем число дочерних узлов
? oXMLRoot.childNodes.length
При исполнении последней команды получим значение 2. Это значение будет определять число записей в будущем курсоре
Идем дальше, имея в виду структуру нашего XML-документа. Получим первый дочерний узел корневого узла.
oFirstNode=oXMLRoot.firstChild
Это соответствует уровню записи. (далее по тексту, я буду называть первый и второй дочерние узлы корневого узла "записями", что соответствует физическому смыслу этих узлов). То есть, все что содержится внутри этого узла, представляет собой содержимое записи. Имена полей этой записи будут соответствовать именам дочерних узлов этого узла. Но у этого узла имеется четыре дочерних узла...
? oFirstNode.childNodes.length
... (смотрим структуру XML-файла) один "dbname" и три "tables".
Что будет определять поля курсора? Имена узлов. Узлов на уровне записи четыре, а для их имен используются два значения - dbname и tables. Поэтому будет сформировано два поля и их имена будут соответствовать именам узлов.
oFirstField=oFirstNode.firstChild
? oFirstField.nodeName
oSecondField=oFirstField.nextSibling
? oSecondField.nodeName
Вернемся к структуре XML-документа. Первое "поле" представляет собой простой тип элемента. Значение первого поля равно значению, содержащемуся между тэгами <dbname></dbname> и его можно получить двумя способами - либо обращением к свойству узла text либо к свойству узла nodeTypedValue.
? oFirstField.text
? oFirstField.nodeTypedValue
Со вторым полей все несколько сложнее - это комплексный элемент, содержащий внутри себя некоторую последовательность элементов. Посмотрим, что вернет свойство text второго поля:
? oSecondField.text
? oSecondField.nodeTypedValue
В результате исполнения двух строк кода, приведенного выше, получим: "Projects id description remarks". То есть очищенное от внутренних тэгов содержимое, заключенное между тэгами <tables></tables>. Но в курсор записывается содержимое последнего узла этого уровня иерархии. Аналогично и со второй "записью".
oSecondNode=oFirstNode.nextSibling
? oSecondNode.childNodes.length
При разборе парсером все происходит также, как и в случае с первой "записью" и в курсор, в поле "tables" попадает значение последнего узла данного уровня иерархии.
А что сделают другие программы, которые могут открывать файлы этого формата? Откроем этот же файл в Microsoft Excel 2003 - для начала, как XML List, как первую из представленных возможностей. При открытии файла мы получим предупреждение, что XML-документ не содержит ссылки на схему и она будет создана на основе данных исходного документа.
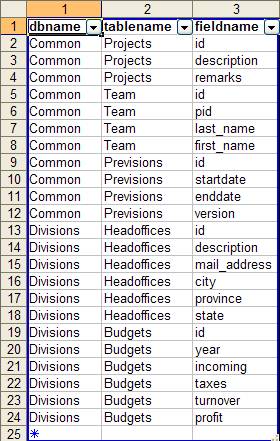
После чего, мы получим Excel'евский список, содержание которого показано на рисунке ниже:
Одновременно с этим, Excel составит схему, которую можно посмотреть в Task Pane (показано на рисунке ниже):
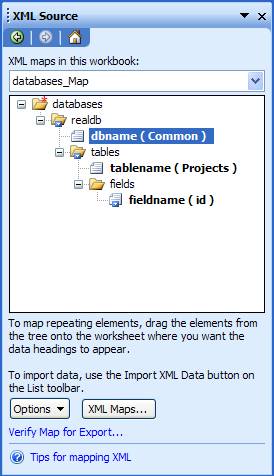
К схемам мы вернемся в одной из статей этого цикла.
Этот же файл, открытый в Excel как рабочая книга, с аттрибутом "только для чтения" - (As Read-only Workbook) будет выглядеть совсем по иному (показано на рисунке ниже:
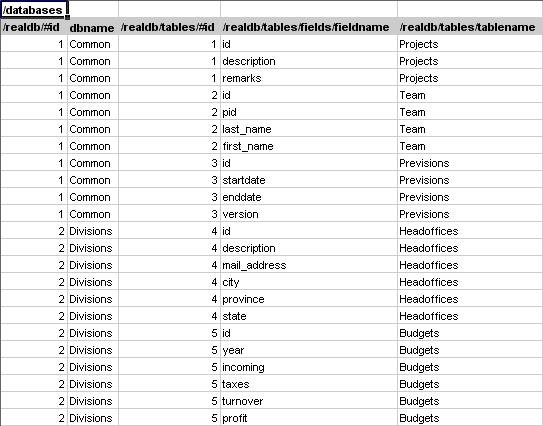
Информация из файла перенесена без потерь, кроме того, добавлены две колонки идентификаторов - одна на уровня realdb, другая для - tables.
Добавим к нашему файлу файл трансформации с помощью таблицы стилей.
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output version="1.0" encoding="utf-8" omit-xml-declaration="no"
indent="no" media-type="text/html" />
<xsl:template match="/">
<html>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<head>
<title>Second XML</title>
</head>
<body>
<xsl:for-each select="databases">
<table border="1">
<thead>
<tr>
<th>Database name</th>
<th>Tables & structure</th>
</tr>
</thead>
<tbody>
<xsl:for-each select="realdb">
<tr>
<td>
<xsl:for-each select="dbname">
<xsl:apply-templates />
</xsl:for-each>
</td>
<td>
<xsl:for-each select="tables">
<table border="1" width="100%">
<thead>
<tr>
<th>Table name</th>
<th>Structure</th>
</tr>
</thead>
<tbody>
<tr>
<td>
<xsl:for-each select="tablename">
<xsl:apply-templates />
</xsl:for-each>
</td>
<td>
<xsl:for-each select="fields">
<table border="1" width="100%">
<thead>
<tr><th>Field name</th></tr>
</thead>
<tbody>
<xsl:for-each select="fieldname">
<tr>
<td>
<xsl:apply-templates />
</td>
</tr>
</xsl:for-each>
</tbody>
</table>
</xsl:for-each>
</td>
</tr>
</tbody>
</table>
</xsl:for-each>
</td>
</tr>
</xsl:for-each>
</tbody>
</table>
</xsl:for-each>
</body>
</html>
</xsl:template>
</xsl:stylesheet>
Изменим пролог нашего файла "second_no_xslt.xml":
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="C:\VFPTests\second_xslt.xslt"?>
и сохраним его как "second_xslt.xml". Этот файл можно взять здесь, а файл трансформации здесь. Сохраните оба файла в каталог C:\VFPTests и откройте файл "second_xslt.xml" в Internet Explorer. Вы должны получить такую картинку:
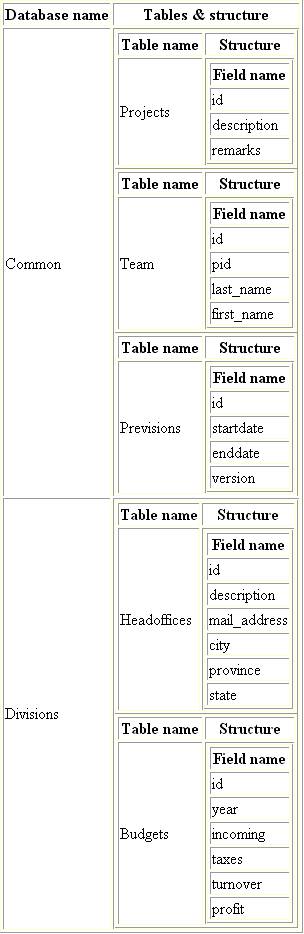
А так этот файл выглядит в моем редакторе XML/XSD файлов.
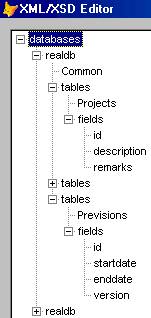
Можно подвести первый итог: три программы МОГУТ "читать" один и тот же файл, но "читают" по разному. Причем в случае VFP, при использовании функции XMLTOCURSOR() налицо совершенно законная потеря данных и информативности, из-за несоответствия структур XML-документа и родных таблиц, а для "красивого" отображения в Интернет Explorer требуется дополнительный файл стилевой трансляции.
Однако, если XML-документ сформирован в Visual FoxPro и им же преобразован в курсор, то это является очень удобным средством обмена данных и мы вернемся к этому позже, в одной из статей этого цикла.
|